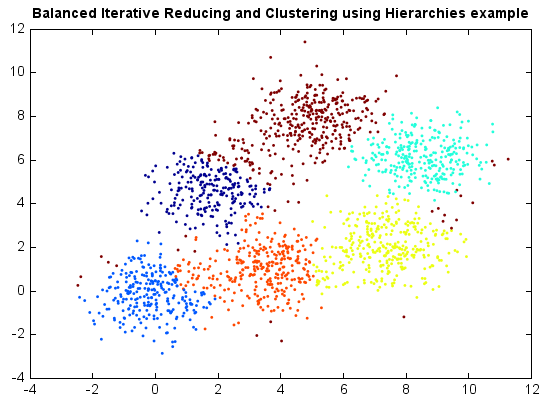
Balanced Iterative Reducing and Clustering using Hierarchies¶
BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies) performs hierarchical clustering over particularly large datasets. An advantage of BIRCH is its ability to incrementally and dynamically cluster incoming, multi-dimensional metric data points in an attempt to produce the high quality clustering for a given set of resources (memory and time constraints).
BIRCH has several advantages. For example, each clustering decision is made without scanning all data points and currently existing clusters. It exploits the observation that data space is not usually uniformly occupied and not every data point is equally important. It makes full use of available memory to derive the finest possible sub-clusters while minimizing I/O costs. It is also an incremental method that does not require the whole data set in advance.
from miml import datasets
from miml.cluster import BIRCH
fn = os.path.join(datasets.get_data_home(), 'clustering', 'gaussian',
'six.txt')
df = DataFrame.read_table(fn, header=None, names=['x1','x2'],
format='%2f')
x = df.values
k = 6
model = BIRCH(k, min_pts=3, branch=10, radius=1)
y = model.fit_predict(x)
cols = makecolors(k)
scatter(x[:,0], x[:,1], c=y, edgecolor=None, s=3, levels=range(k), colors=cols)
title('Balanced Iterative Reducing and Clustering using Hierarchies example')