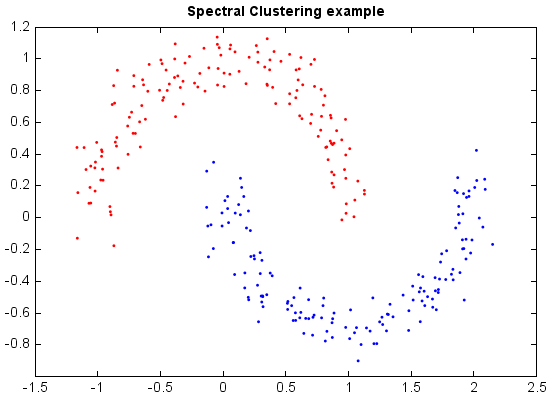
Spectral Clustering¶
Given a set of data points, the similarity matrix may be defined as a matrix S where Sij represents a measure of the similarity between points. Spectral clustering techniques make use of the spectrum of the similarity matrix of the data to perform dimensionality reduction for clustering in fewer dimensions. Then the clustering will be performed in the dimension-reduce space, in which clusters of non-convex shape may become tight. There are some intriguing similarities between spectral clustering methods and kernel PCA, which has been empirically observed to perform clustering.
from miml import datasets
from miml.cluster import SpectralClustering
fn = os.path.join(datasets.get_data_home(), 'clustering', 'nonconvex',
'sincos.txt')
df = DataFrame.read_table(fn, header=None, names=['x1','x2'],
format='%2f')
x = df.values
model = SpectralClustering(2, sigma=0.2)
y = model.fit_predict(x)
scatter(x[:,0], x[:,1], c=y, edgecolor=None, s=3, levs=[0,1], colors=['r','b'])
title('Spectral Clustering example')